
Gradients all the way down.
Every PropTorch call is an autograd node. loss.backward() populates vp.grad as an ordinary torch Tensor — feed it to any optimizer.
Scale across GPUs.
Wrap the inversion in torchrun --nproc_per_node=4 and shots distribute themselves. Marmousi FWI hits 3.79× on 4 × V100.
Acoustic to TTI, 2D and 3D.
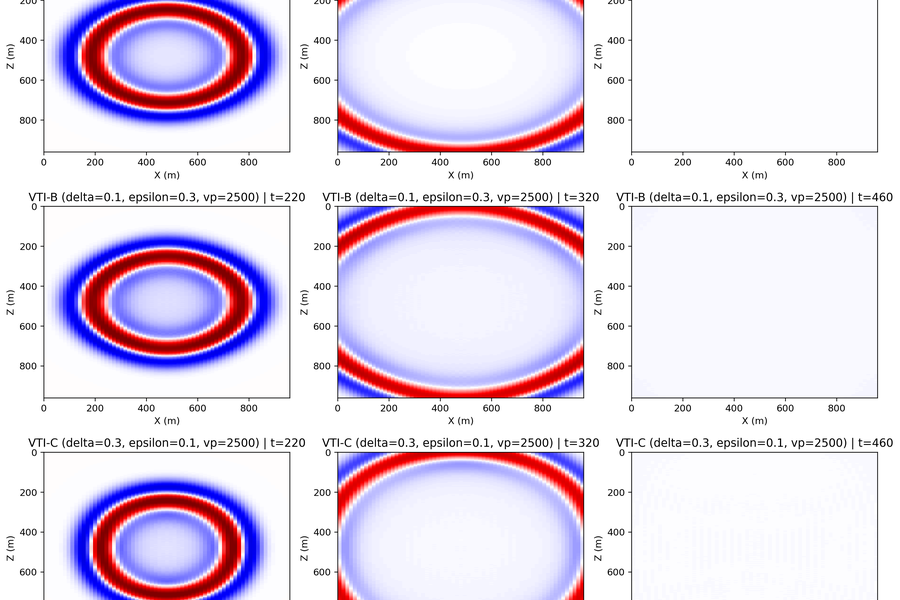
33 equation classes across nine families — Acoustic, Elastic, VTI, TTI, LSRTM-Born, DAS. PML and sponge boundaries. Same solver API for all of them.
Learn moreOne file.
Forward → loss → backward.¶
A two-layer truth, one shot, sixty-four receivers — and a single .backward() hands you the velocity gradient.
import numpy as np, torch
from sweep.equations import Acoustic
from sweep.propagator.torch import PropTorch
from sweep.signal import ricker
dev = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
solver = PropTorch(Acoustic(device=dev),
shape=(96, 128), dh=10.0, dt=2e-3, dev=dev)
wavelet = ricker(np.arange(600) * 2e-3 - 0.12, f=10.0).astype(np.float32)
sources = np.array([[64, 2]], dtype=np.int64)
receivers = np.array([[[ix, 4] for ix in range(0, 128, 2)]], dtype=np.int64)
vp = torch.tensor(vp_init, device=dev, requires_grad=True)
pred = solver(wavelet, sources, receivers, models=[vp])
loss = 0.5 * (pred - obs).pow(2).sum()
loss.backward() # vp.grad ready for any torch.optim step
Acoustic. Elastic.
VTI. TTI.
Nine equation classes, one solver API. Swap Acoustic for ElasticTTI without touching your inversion loop.
from sweep.equations import ElasticTTI

Adam, L-BFGS, or write
your own.
Gradients are torch Tensors. eps=1e-16 on Adam keeps tiny FWI gradients from getting masked.
torch.optim.Adam([vp], lr=25.0, eps=1e-16)

Pre-baked notebooks.
Every cell already executed. Read in the browser, or download to run locally.

Built on what you already trust.
Lazy imports — only the backend you actually use is loaded.